En la unidad numero 2 del curso de Biología Molecular; se hablara sobre la estructura química y física de los ácidos nucleicos; que son el ADN y ARN. En este punto se estudiara, se describirá, y se conocerán todas aquellas características químicas y físicas que estas moléculas presentan, también se hablara sobre las funciones que presentan estas moléculas, cuales son, como son, y gracias a que son realizadas y la importancia de estos procesos.
2.1. ESTRUCTURA QUÍMICA Y FÍSICA DE LOS ÁCIDOS
NUCLEICOS: ADN Y ARN.
*Fosfatos: Proporciona el carácter eminentemente ácido del
DNA y del RNA.
Características
Químicas del ADN
|
Características
Químicas ARN
|
Presentan un azúcar desoxirribosa
|
Presenta un azúcar Ribosa
|
Contiene un grupo fosfato
|
Contiene un grupo fosfato
|
Y una base nitrogenada
|
Y una base Nitrogenada
|
A.T.G.C
|
A.U.G.C
|
Características
Físicas del ADN
|
Características
Físicas del ARN
|
Doble Hélice
|
Cadena Sencilla
|
Anti paralela
|
Presenta diferentes formas
|
Las cadenas se unen por puentes de Hidrógeno de bases nitrogenadas
|
Lineal: ARNm
|
Helicoidales
|
Globular: ARNm
|
Dextrogira
|
Trébol: ARNt
|
Presenta surco mayor y surco menor
|
*Pentosas: Es el componente neutro, y sólo hay dos en los
ácidos nucleicos
*Bases Nitrogenadas: Se encargan de darle la especificidad y el caracter básico a los ácidos nucleicos. Derivan del anillo de pirimidina o del doble anillo de purina .
ESTRUCTURA QUÍMICA
*Bases Nitrogenadas: Se encargan de darle la especificidad y el caracter básico a los ácidos nucleicos. Derivan del anillo de pirimidina o del doble anillo de purina .
ESTRUCTURA QUÍMICA
Compuesto sólo de cuatro
moléculas básicas, llamadas nucleótidos, idénticas entre si, excepto que cada
uno contiene una base nitrogenada diferente.
Cada nucleótido contiene:
·
Un grupo fosfato,
·
Un azúcar (desoxirribosa= para el ADN) y
(ribosa= para el ARN),
·
Una de las cuatro bases (A,G,C,T= para el ADN) y
(A,G,C,U= para el ARN)
En ausencia del grupo fosfato, la base y el azúcar forman un nucleósido, en vez de un nucleótido.
Las cuatro bases del ADN son adenina, guanina, citosina y timina. Los nombres químicos completos son: 5´-monofosfato de desoxiadenosina, 5´-monofosfato de desoxiguanosina, 5´-monofosfato de desoxicitosina, 5´-monofosfato de desoxitimidina. Sin embargo corrientemente se refiere a cada nucleotido por la abreviatura de su base (A, G, C y T respectivamente).
Dos de las bases, adenina y guanina son de estructura similar y se denomina purinas, las otras dos citosina y timina, también son similares y se denominan pirimidinas.
Los ácidos nucleicos están constituidos entonces por la unión de numerosos nucleótidos. Cada nucleótido esta formado por un nucleósido y un fosfato (ácido) . El nucleósido está formado por una pentosa (neutro) y una base nitrogenada (básica).


ESTRUCTURA FISICA
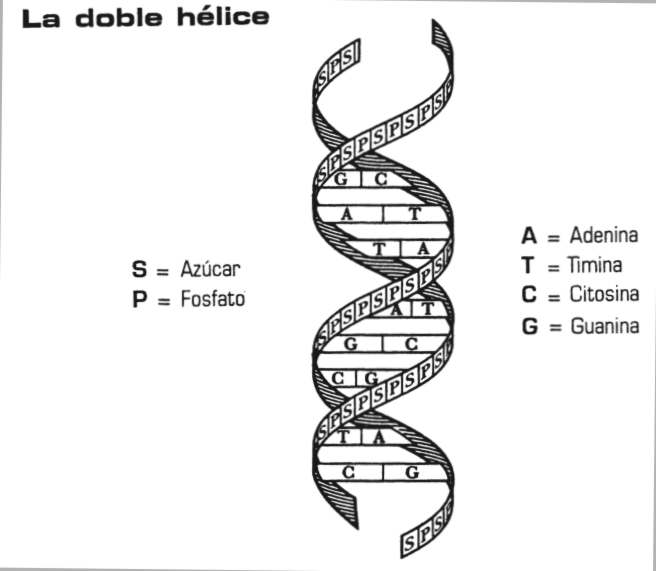
La doble hélice del
ADN
La estructura que diseñaron Watson y Crick en 1953 es una doble hélice, cada hélice es una ristra de nucleótidos unidos por enlaces fosfodiester, en el que un grupo fosfato forma un puente entre grupos –OH de dos residuos de azúcar adyacentes.
Las dos hélices se mantienen juntas mediante puentes de hidrógeno. Los puentes de hidrogeno se dan entre átomos de hidrógeno con una pequeña carga positiva y átomos con pequeña carga negativa.
Watson y Crick demostraron que
solo estos emparejamientos poseen la complementariedad necesaria tipo “llave-cerradura”,
para que permitiera la formación de puentes de hidrogeno.
El par G-C forma 3
puentes de hidrogeno, mientras que el par A-T solo dos. Se predijo que el DNA que tuviera muchos pares G-C seria más estable que el DNA
con muchos pares A-T, y de hecho esta predicción fue confirmada.
Otras Estructuras
Las estructuras más frecuentes y
fisiológicas en las que se puede encontrar el DNA es en forma de DNA-B (la
propuesta de Watson y Crick), en forma de DNA-A (cuando está deshidratado o
hibridado con RNA) y DNA-Z (cuando es levógiro).
Características de las formas del ADN
Características del DNA-B
|
Características del DNA-A (También llamado RNA 11) |
Giro de la hélice: Dextrógiro Diámetro de la hélice: 2,37 nm Del diámetro, 1,1 nm corresponde al par de bases . Vuelta completa: (Paso de rosca, pitch): 3,54 nm Nucleótidos por vuelta: 10,4 pb (Watson y Crick propusieron 10) Separación entre las bases (elevación o rise): 0,34 nm (3,54 / 10,4 = 0,34), que además coincide con el tamaño de van der Waals para un anillo plano. |
Giro de la hélice: Dextrógiro Diámetro de la hélice: 2,55 nm Del diámetro, 1,1 nm corresponden al par de bases, pero no se sitúan sobre el eje como en el DNA-B, dejando un hueco central en el que puede entrar el agua. Vuelta completa: (Paso de rosca, pitch) 2,53 nm Nucleótidos por vuelta: 11 pb (de aquí el nombre de DNA-11) |
2.2 FUNCIÓN DE LOS ÁCIDOS NUCLEICOS.
El dogma central de la Biologia Molecular
Fue Francis Crick quien introdujo el dogma central de la
Biología Molecular parar describir el flujo de información biológica y cómo la
célula utiliza esa información. 
Implicaciones
biológicas de la estructura del DNA
Esta estructura del DNA causó gran excitación entre los
genetistas y en todas las áreas de la biología, por 2 razones fundamentales:
1. La estructura sugería una forma obvia por la que la molécula puede ser duplicada o replicada, ya que cada base determina su complementaria mediante puentes de hidrogeno.
2. La estructura hace pensar que quizá la secuencia de pares de bases en el DNA es la que determina la secuencia de aminoácidos de la proteína dictada por un gen. En otras palabras, algún tipo de código genético podría escribir información en el DNA con una secuencia de pares de nucleótidos.
3. Por iguales razones la estructura guarda y trasmite la información genética.
2. La estructura hace pensar que quizá la secuencia de pares de bases en el DNA es la que determina la secuencia de aminoácidos de la proteína dictada por un gen. En otras palabras, algún tipo de código genético podría escribir información en el DNA con una secuencia de pares de nucleótidos.
3. Por iguales razones la estructura guarda y trasmite la información genética.
Funciones ARN
|
Funciones ADN
|
ARNm: Informativo; Llevar la información del ADN a los ribosomas para
producir proteínas
ARNr: Se encarga de unir los aminoácidos en proteínas con la información
del ARNm
ARNt: Transportar los aminoácidos al Ribosoma
ARNsn: Corta los intrones y exones en ARNm inmaduro en el núcleo.
ARNsc: Ayuda en el transporte de proteínas en el citoplasma dentro de
la célula
|
Contiene y guarda el material genético, guarda la información genética
Copia y replica la información, se copia así mismo
Controla el metabolismo de la Célula.
|








